
Our deepfake problem is about to get worse: Samsung engineers have now developed realistic talking heads that can be generated from a single image, so AI can even put words in the mouth of the Mona Lisa.
The new algorithms, developed by a team from the Samsung AI Center and the Skolkovo Institute of Science and Technology, both in Moscow work best with a variety of sample images taken at different angles – but they can be quite effective with just one picture to work from, even a painting.
 (Egor Zakharov)
(Egor Zakharov)
Not only can the new model work from a smaller initial database of pictures, it can also produce computer-generated videos in a shorter time, according to the researchers behind it.
And while there are all kinds of cool applications that the technology could be used for – such as putting an ultra-realistic version of yourself in virtual reality – it's also worrying that completely fake video footage can be produced from as little as one picture.
"Such ability has practical applications for telepresence, including videoconferencing and multi-player games, as well as the special effects industry," write the researchers in their paper.
 (Egor Zakharov)
(Egor Zakharov)
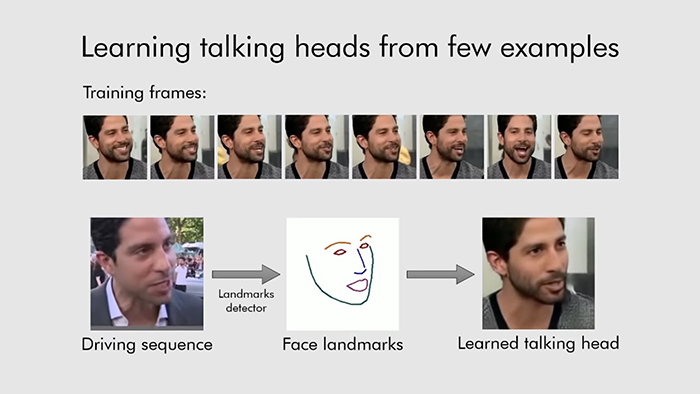
The system works by training itself on a series of landmark facial features that can then be manipulated. A lot of the training was done on a publicly available database of more than 7,000 images of celebrities, called VoxCeleb, plus a huge number of videos of people talking to the camera.
Where this new approach improves on past work is by teaching the neural network how to convert landmark facial features into realistic-looking moving video many times over. That knowledge can then be deployed on a few pictures (or just one picture) of someone the AI has never seen before.
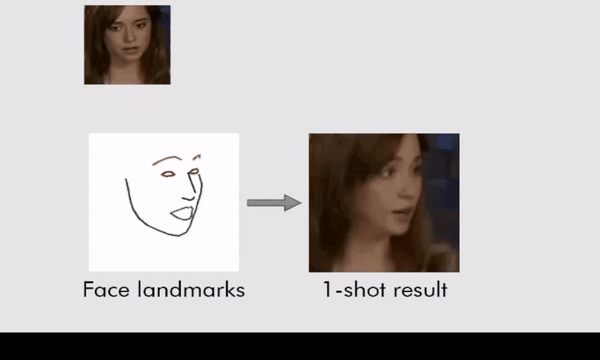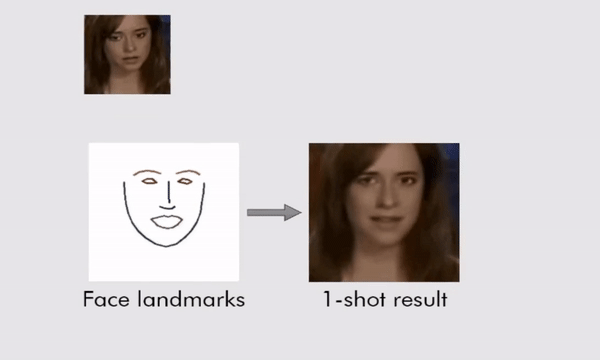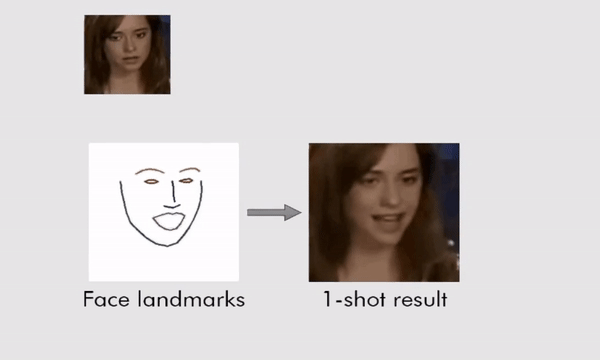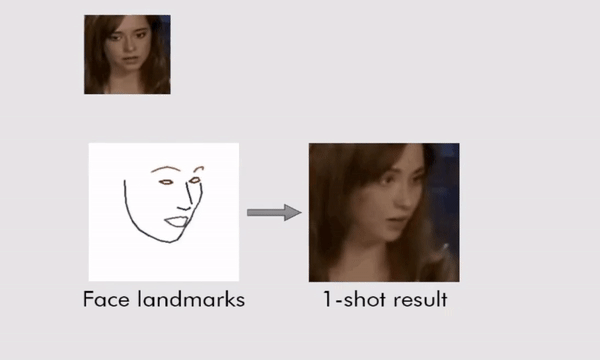 (Egor Zakharov)
(Egor Zakharov)
The system makes use of a convolution neural network, a type of neural network based on biological processes in the animal visual cortex. It's particularly adept at processing stacks of images and recognising what's in them – the "convolution" essentially recognises and extracts parts of images (it's also used in image searches on the web and self-driving car technology, for instance).
 (Samsung AI Center)
(Samsung AI Center)
Like other AI-driven face generation tools we've seen, the last stage in the process checks for 'perfect realism' – technically an adversarial generative model. Any frames that look too weird or unnatural get cut and rendered again, leaving a better quality final video.
This technique manages to overcome two big problems in artificially generated talking heads: the complexity of heads (with mouths, hair, eyes and so on), and our ability to easily spot a fake head (character faces are among the hardest elements for video game designers to get right, for example).
The system, and others like it, are bound to get better as algorithms improve and training models become more efficient – and that means a whole new set of questions about whether you can trust what you're seeing or hearing if it's in digital form.
On the plus side, your favourite movie and TV stars never have to grow old and die – AI similar to this is soon going to be smart enough to produce fully realistic performances from just a few photographs, and in record time, too.
Just remember that seeing isn't always believing any more.
The research has been published on the pre-print server arXiv.org.