
Researchers have developed a new tool, powered by artificial intelligence, that can create realistic-looking videos of speech from any audio clip, and they've demoed the tech by synthesising four artificial videos of Barack Obama saying the same lines.
The tool isn't intended to create a flurry of fake news and put false words in people's mouths though – it's designed partly as a way to eventually spot forgeries and videos that aren't all they appear to be.
According to the team from the University of Washington, as long as there's an audio source to use, the video can include realistic mouth shapes that are almost perfectly aligned to the words being spoken. Those synthesised shapes can then be grafted onto an existing video of someone talking.
"These type of results have never been shown before," says one of the researchers, Ira Kemelmacher-Shlizerman. "Realistic audio-to-video conversion has practical applications like improving video conferencing for meetings, as well as futuristic ones such as being able to hold a conversation with a historical figure in virtual reality."
"This is the kind of breakthrough that will help enable those next steps."
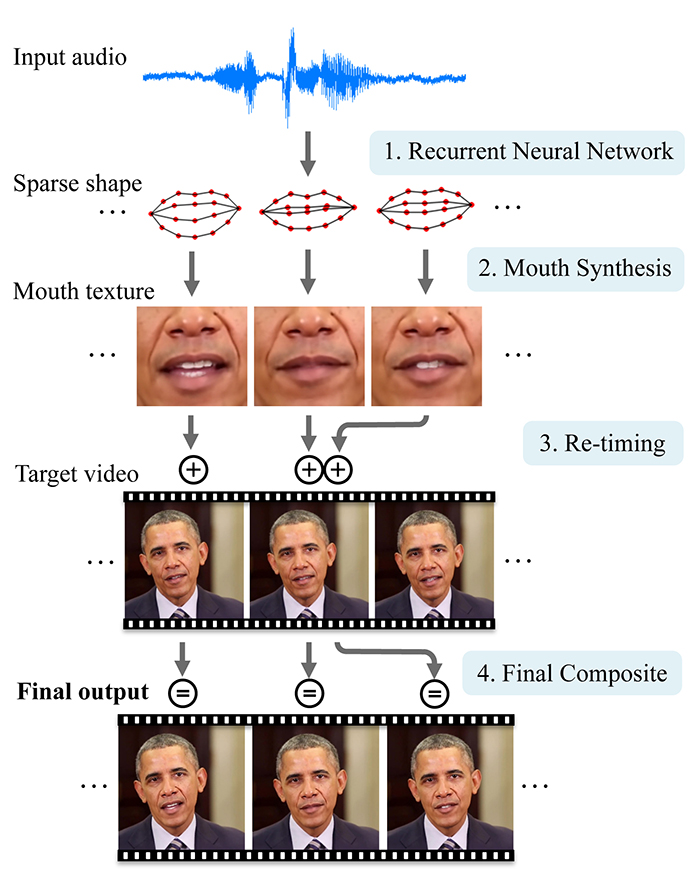 The video synthesising stages. Credit: University of Washington
The video synthesising stages. Credit: University of Washington
There are two parts to the system: first a neural network is trained to watch large volumes of videos to recognise which audio sounds match with which mouth shapes. Then the results are mixed with moving images of a specific person, based on previous research into digital modelling carried out at UW.
The tool is impressively good, as you can see from the demo clips (below), but it needs source audio and video files to work from, and can't generate speeches from thin air. In the future, the researchers say, the AI system could be trained using video from messaging apps, and then used to enhance their quality.
"When you watch Skype or Google Hangouts, often the connection is stuttery and low-resolution and really unpleasant, but often the audio is pretty good," says one of the team, Steve Seitz. "So if you could use the audio to produce much higher-quality video, that would be terrific."
When it comes to spotting fake video, the algorithm used here could be reversed to detect clips that have been doctored, according to the researchers.
You can see the tool in action below:

As you might know from video games and animated movies, scientists are working hard to solve the "uncanny valley" problem, where computer-generated video of someone talking looks almost right but still somehow off-putting.
In this case the AI system does all the heavy lifting when it comes to working out mouth shape, chin position, and the other elements needed to make a clip of someone talking look realistic.
Artificial intelligence excels at machine learning problems like this, where masses of data can be analysed to teach computer systems to do something – whether that's recognising dogs in an image search or producing natural-looking video.
"There are millions of hours of video that already exist from interviews, video chats, movies, television programs and other sources," says lead researcher Supasorn Suwajanakorn. "And these deep learning algorithms are very data hungry, so it's a good match to do it this way."
It's another slightly scary step forward in the quality of digital fakery, similar to Adobe's Project VoCo, which we saw last year – another AI system that can produce new speech out of thin air after studying just 20 minutes of someone talking.
However, this particular neural network has been designed to work with just one individual at a time using authentic audio clips, so you can still trust the footage you see on the news for a while yet.
"We very consciously decided against going down the path of putting other people's words into someone's mouth," says Seitz. "We're simply taking real words that someone spoke and turning them into realistic video of that individual."
The research is being presented at the SIGGRAPH 2017 computer graphics conference and you can read the paper here.