Humans evolved to look on the bright side of life, and this 'positivity bias' has been built into our language, the results of a massive examination of the words used in 10 different languages has shown.
The basis of this research harkens back to 1969, when two psychologists at the University of Illinois came up with the so-called Pollyanna Hypothesis - that humans universally tend to skew their use of language towards happy words, rather than negative ones. "Put even more simply," the pair wrote, "humans tend to look on (and talk about) the bright side of life." But this was just an hypothesis, they had little evidence to back it up, and it has inspired heated debate ever since.
So researchers in the US, from the University of Vermont (UoV) and not-for-profit research and development organisation, the MITRE Corporation, decided to look for that evidence in the most logical place - words used by actual humans, professionally, online, and in everyday life. They collected billions of words from 10 different languages, sourced from 24 types of text including books, news outlets, social media, websites, television and movie subtitles, and music lyrics. To give you an idea of the scope - "We collected roughly 100 billion words written in tweets," one of the team, mathematician Chris Danforth from UoV, said in a press release.
Once they had all their data, the team figured out what were the 10,000 most frequently used words in each of the languages - English, Spanish, French, German, Brazilian Portuguese, Korean, Chinese (simplified), Russian, Indonesian and Arabic. Fifty native speakers were then hired to rate these words according to how 'happy' or 'sad' they considered them to be on a nine-point scale from a very sad frowny face at 1 to a broadly smiling face at 10. From these ratings, they collected 5 million individual human scores of the words, and averaged them out. The results in English, for example, included "laughter" with an average rating of 8.50, "food" with 7.44, "truck" 5.48, "the" 4.98, "greed" 3.06 and "terrorist" 1.30.
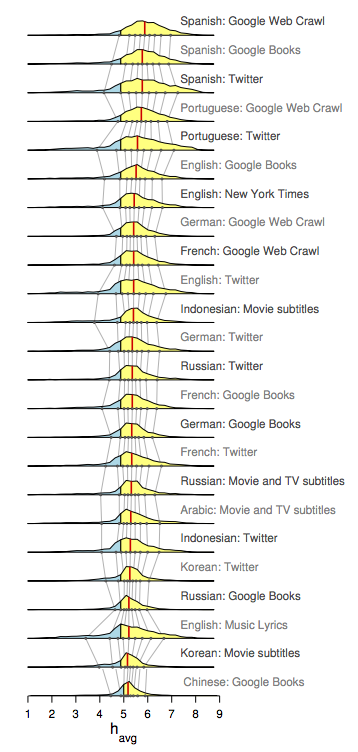
Using these averages, the team hit Google to see how often these words are used online. Publishing in the Proceedings of the National Academy of Sciences, the team reports that Spanish-language websites had the highest average 'word happiness', and Chinese books had the lowest. But of all 24 sources of words they examined, every single one, regardless of the language, skewed above the neutral score of 5 on their sad words-happy words scale. "In every source we looked at, people use more positive words than negative ones," said UoV mathematician Peter Dodds, who co-led the study with Danforth.
On average, we "use more happy words than sad words," added Danforth.
John Bohannon explains the results, which you can see below, at Science:
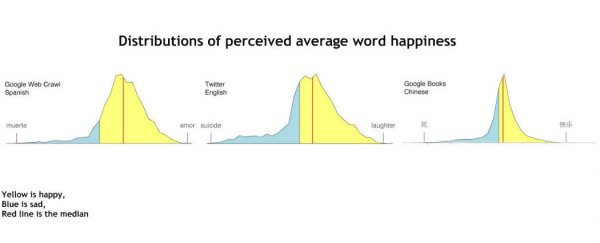
"Graphs of the data show that the Pollyanna principle is indeed part of language itself. If there were no bias, then the median emotional values of the words (red lines) would fall in the middle of the emotional scale. But instead, the median emotional resonance of words falls well into positive territory for every corpus from every language tested."
 Credit: Dodds et al., PNAS
Credit: Dodds et al., PNAS
You can download the entire data set here.
The study is part of a larger project to build a new kind of happiness meter - called a hedonometer - which can track the 'happiness signals' in English-language Twitter posts on an almost real-time basis, so you can see how they differ between the days, weeks, and months. Already their new hedonometer has revealed the obvious - that on the day of the Charlie Hebdo attack in Paris, language use on Twitter was much more sombre than usual - and the intriguing - that in the US, the state of Vermont has the highest happiness signal, while Louisiana has the lowest. In US cities, Boulder in Colorado has the happiest signal, while Racine in Wisconsin has the lowest.
While their hedonometer can only track English language tweets right now, the team is hoping to expand its capabilities to include many other languages and sources. They've just started applying it to 10,000 books, and have so far found that in Herman Melville's classic, Moby Dick, the novel's 170,914 words form four or five major valleys that match the low points in the story, and the hedonometer gives the ending a super-low happiness signal, while in Alexandre Dumas's Count of Monte Cristo - consisting of 100,081 words in French - the language used at the end is jubilant.
What we can glean from this research is that the hypothesised human tendency to lean towards the positive side of things is borne out, unconsciously, in the language we speak. And Bohannon brings up an interesting point for future research - if use of happy words is inconstant across languages, for example, Spanish language uses more happy words than Chinese, does this mean using a different language could make you happier? Quick, someone tell Henri:

Source: Science