Scientists have filled in millions of missing pieces of human DNA, yielding the most complete, gapless sequence of the human genome ever produced, bar one tiny chromosome.
The feat, made possible by ever-improving genome sequencing technologies and a consortium of more than 100 scientists, sets a new benchmark for understanding human genetic diversity in all its glory.
The team has also corrected thousands of structural errors in our previous most complete reference genome during the process. The achievement cannot be understated: It holds huge potential for better understanding human evolution and disease.
"Truly finishing the human genome sequence was like putting on a new pair of glasses," says bioinformatician Adam Phillippy of the US National Human Genome Research Institute.
"Now that we can clearly see everything, we are one step closer to understanding what it all means."
Ever since the launch of the Human Genome Project more than 30 years ago, genetic sequencing technologies and data-processing pipelines have been getting faster, cheaper and more precise, allowing researchers to sample, sequence and compare more genomes with every passing year.
But huge chunks of DNA – amounting to around 8 percent of the human genome – were still missing from the most recent reference sequence that scientists use as a template to assemble newly-sequenced DNA samples.
Now, scientists have pieced together those parts of the human genome which have long been 'unsequenceable' to assemble the most complete reference genome to date, sharing their findings in a collection of six papers, published in the journal Science.
The herculean research effort adds approximately 200 million base pairs of genetic information – a full chromosome's worth – to the human genome. Most of these are located in telomeres, the protective caps on the end of each chromosome, and in the dense middle sections of chromosomes, called centromeres.
"Finally, from tip to tip, telomere to telomere, we have an assembly of the genome we can look at," says Winston Timp, a biomedical engineer at Johns Hopkins University.
It's wild to think there were so many gaps in the human genome as we knew it; millions of missing bases, in fact. But it speaks to the beguiling beauty and sheer complexity of the bucketloads of DNA crammed inside our cells, encoding every intimate detail of life.
"We've gotten an enormous understanding of human biology and disease from having roughly 90 percent of the human genome," says bioinformatician David Haussler of the University of California (UC) Santa Cruz Genomics Institute.
"But there were many important aspects that lay hidden, out of view of science, because we did not have the technology to read those portions of the genome."
Scientists first mapped the human genome decades ago by piecing together and overlaying 'short reads' of DNA that captured only several hundred bases at a time. Then, long-read sequencing enabled them to make sense of previously 'unreadable' repetitive chunks of DNA that had long defied research.
"These parts of the human genome that we haven't been able to study for 20-plus years are important to our understanding of how the genome works, genetic diseases, and human diversity and evolution," says UC Santa Cruz geneticist Karen Miga, who headed up the consortium of researchers.
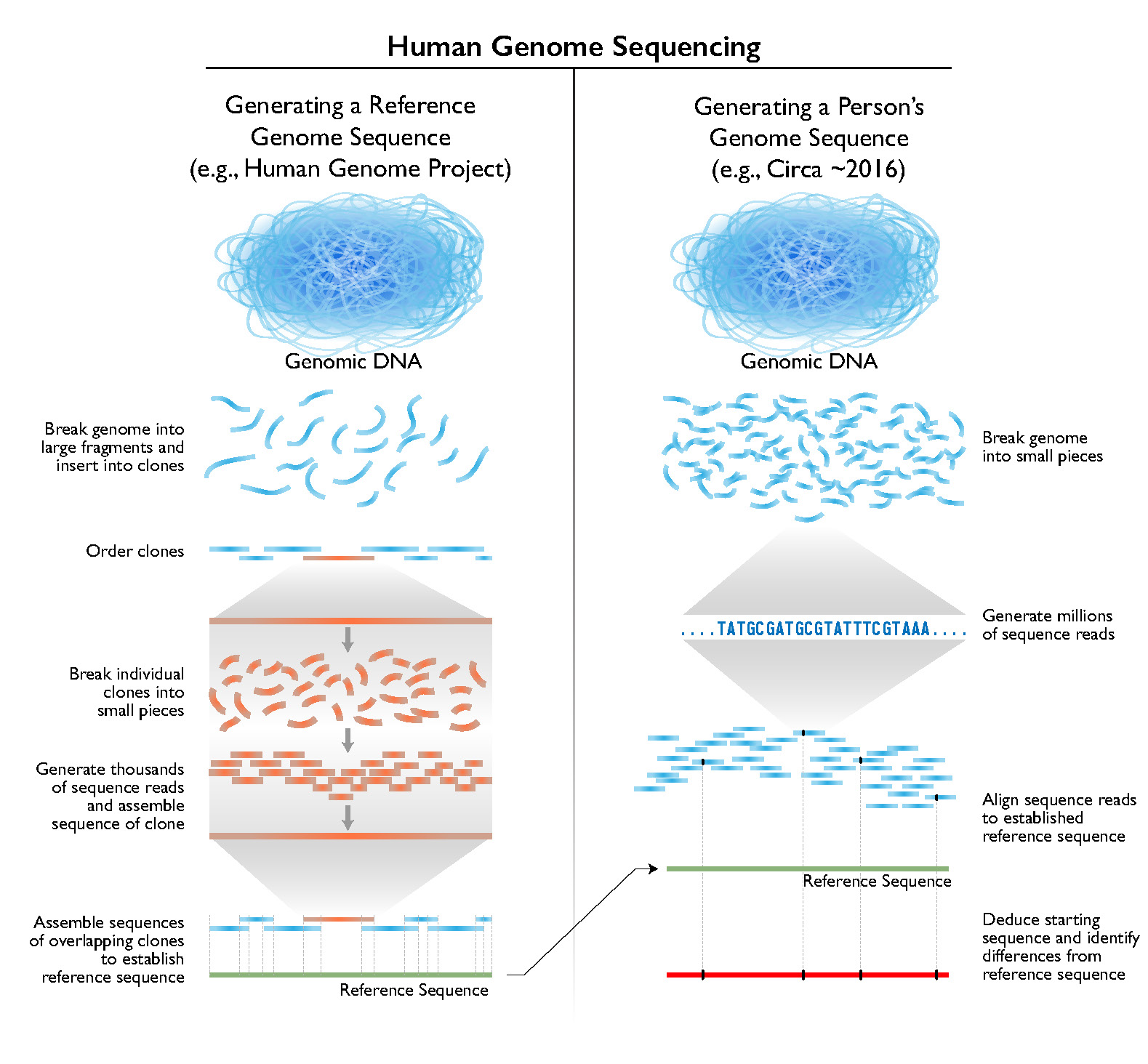 Human genome sequencing methods. (NIH)
Human genome sequencing methods. (NIH)
The new 'gapless' genome, which now totals over 3 billion bases, could also shed light on how pairs of chromosomes get pulled apart and divide without a hitch, the mechanics of so-called jumping genes that hop around the genome, and the perhaps-crucial role of long stretches of duplicative DNA.
"Opening up these new parts of the genome, we think there will be genetic variation contributing to many different traits and disease risk," says evolutionary biologist Rajiv McCoy of Johns Hopkins University. But he adds, "there's an aspect of this that's like, we don't know yet what we don't know".
Rather than being a mosaic of sequences collated from multiple individuals, the newly-minted reference genome was put together using a special type of cell line that has two identical copies of each chromosome (unlike most human cells, which carry two slightly different copies).
That means there's still lots of work to be done to finalize the reference genome (the Y chromosome still needs to be finished) but the group is inching ever closer to finally sequencing every last nucleotide of human DNA.
While researchers have high hopes that the near-complete genome, dubbed T2T-CHM13, could pave the way toward a more inclusive representation of human diversity, the field at large is still grappling with how to resolve historical injustices in genome science and the lack of diversity in genetic studies which threatens to exacerbate healthcare disparities.
However, teams of scientists have already used the near-complete reference sequence to uncover more than 2 million previously unknown variants in the human genome, all of which will enrich our understanding of how individual genetic differences can contribute to certain diseases.
Of course, time will tell if personalized medicine can truly live up to its promise of delivering affordable, targeted treatments based on an individual's genetic make-up, but researchers are excited.
"In the future, when someone has their genome sequenced, we will be able to identify all of the variants in their DNA and use that information to better guide their healthcare," says Phillippy.
The research was published in Science.