
The discovery of the extraordinary exoplanet LTT 9779b was first announced a month ago. Just 260 light-years away, the planet was immediately pegged as an excellent candidate for follow-up study of its curious atmosphere. But it turns out we didn't even have to wait too long to learn more.
LTT 9779b is a little bigger than Neptune, orbiting a Sun-like star - fairly normal so far. But two things are really peculiar. It's so close to its star, the planet orbits once every 19 hours; and, in spite of the scorching heat it must be subjected to at that proximity, LTT 9779b still has a substantial atmosphere.
Infrared observations collected by the now-retired Spitzer Space Telescope included the planet's host star, and astronomers have now analysed those data, publishing their results in a couple of studies.
In the first paper, a team led by astronomer Ian Crossfield of the University of Kansas has described LTT 9779b's temperature profile.
In the second paper, a team led by astronomer Diana Dragomir of the University of New Mexico has characterised the exoplanet's atmosphere.
"For the first time, we measured the light coming from this planet that shouldn't exist," Crossfield said.
"This planet is so intensely irradiated by its star that its temperature is over 3,000 degrees Fahrenheit [1,650 degrees Celsius] and its atmosphere could have evaporated entirely. Yet, our Spitzer observations show us its atmosphere via the infrared light the planet emits."
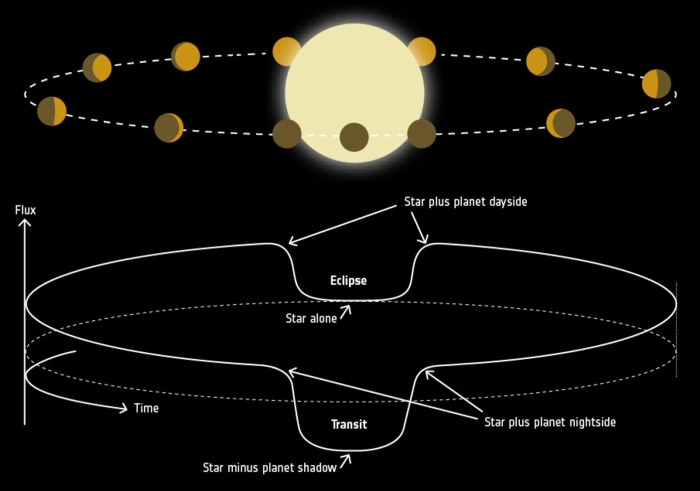 An exoplanet phase curve. (ESA)
An exoplanet phase curve. (ESA)
He and his team studied the exoplanet's phase curve in infrared light. Here's what that means: Because thermal energy is emitted as infrared radiation, light in this wavelength can tell us the temperature of cosmic objects many light-years away.
The system is oriented in such a way that the planet passes between us and the star, giving us clear broadside views of both the planet's night and day sides. Thus, to calculate the exoplanet's temperature, astronomers can use the changing light of the overall system as LTT 9779b orbits.
Interestingly, the hottest time of day for LTT 9779b is just about bang on noon, when its sun is directly overhead. On Earth, the hottest time of day is actually a few hours after noon, because heat enters Earth's atmosphere faster than it is radiated back out into space.
In turn, this allows for some educated guesses about the atmosphere of LTT 9779b.

"The planet is much cooler than we expected, which suggests that it is reflecting away much of the incident starlight that hits it, presumably due to dayside clouds," said astronomer Nicolas Cowan of the Institute for Research on Exoplanets (iREx) and McGill University in Canada.
"The planet also doesn't transport much heat to its nightside, but we think we understand that: The starlight that is absorbed is likely absorbed high in the atmosphere, from whence the energy is quickly radiated back to space."
To further probe the atmosphere of LTT 9779b, Dragomir and her colleagues focused on secondary eclipses, when the planet passes behind the star. This results in a fainter dimming of the system's light than when the planet passes in front of the star - known as a transit - but that fainter dimming can help us understand the thermal structure of an exoplanet's atmosphere.
"Hot Neptunes are rare, and one in such an extreme environment as this one is difficult to explain because its mass isn't large enough to hold on to an atmosphere for very long," Dragomir said.
"So how did it manage? LTT 9779b had us scratching our heads, but the fact that it has an atmosphere gives us a rare way to investigate this type of planet, so we decided to probe it with another telescope."
The researchers combined Spitzer secondary eclipse data with data from NASA's exoplanet-hunting space telescope TESS. This allowed them to obtain an emission spectrum from LTT 9779b's atmosphere; that is, the wavelengths of light absorbed and amplified by elements therein. They found that some wavelengths were being absorbed by molecules - probably carbon monoxide.
This is not unexpected for such a hot planet. Carbon monoxide has been detected in hot Jupiters - gas giants that also orbit their stars at scorchingly close proximity. But gas giants are more massive than hot Neptunes, and use their much higher gravity to retain their atmospheres. It was thought that Neptune-sized planets should not be massive enough to do so.
Finding carbon monoxide in the atmosphere of a hot Neptune could help us understand how this planet formed, and why it still has its atmosphere.
So, while we know more about LTT 9779b than we did, there's still work to be done. Future observations could help us answer these questions and others, such as what else is the atmosphere made of, and did the exoplanet start off much larger, and is currently in the process of rapidly shrinking.
Research like this will give us an excellent toolkit and experience for probing the atmospheres of potentially habitable worlds, too.
"If anyone is going to believe what astronomers say about finding signs of life or oxygen on other worlds, we're going to have to show we can actually do it right on the easy stuff first," Crossfield said.
"In that sense these bigger, hotter planets like LTT 9779b act like training wheels and show that we actually know what we're doing and can get everything right."
The two papers have been published in The Astrophysical Journal Letters, here and here.